注:本文翻译自 Node Topology Manager
概要 #
越来越多的系统将 CPU 和硬件加速器组合使用,以支撑高延迟和搞吞吐量的并行计算。 包括电信、科学计算、机器学习、金融服务和数据分析等领域的工作。这种的混血儿构成了一个高性能环境。
为了达到最优性能,需要对 CPU 隔离、内存和设备的物理位置进行优化。 然而,在 kubernetes 中,这些优化没有一个统一的组件管理。
本次建议提供一个新机制,可以协同 kubernetes 各个组件,对硬件资源的分配可以有不同的细粒度。
启发 #
当前,kubelet 中多个组件决定系统拓扑相关的分配:
- CPU 管理器
- CPU 管理器限制容器可以使用的 CPU。该能力,在 1.8 只实现了一种策略——静态分配。 该策略不支持在容器的生命周期内,动态上下线 CPU。
- 设备管理器
- 设备管理器将某个具体的设备分配给有该设备需求的容器。设备通常是在外围互连线上。 如果设备管理器和 CPU 管理器策略不一致,那么 CPU 和设备之间的所有通信都可能导致处理器互连结构上的额外跳转。
- 容器运行时(CNI)
- 网络接口控制器,包括 SR-IOV 虚拟功能(VF)和套接字有亲和关系,socket 不同,性能不同。
相关问题:
注意,以上所有的关注点都只适用于多套接字系统。 内核能从底层硬件接收精确的拓扑信息(通常是通过 SLIT 表),是正确操作的前提。 更多信息请参考 ACPI 规范的 5.2.16 和 5.2.17 节。
目标 #
- 根据 CPU 管理器和设备管理器的输入,给容器选择最优的 NUMA 亲和节点。
- 集成 kubelet 中其他支持拓扑感知的组件,提供一个统一的内部接口。
非目标 #
- 设备间连接:根据直接设备互连来决定设备分配。此问题不同于套接字局部性。设备间的拓扑关系, 可以都在设备管理器中考虑,可以做到套接字的亲和性。实现这一策略,可以从逐渐支持任何设备之间的拓扑关系。
- 大页:本次提议有 2 个前提,一是集群中的节点已经预分配了大页; 二是操作系统能给容器做好本地页分配(只需要本地内存节点上有空闲的大页即可)。
- 容器网络接口:本次提议不包含修改 CNI。但是,如果 CNI 后续支持拓扑管理, 此次提出的方案应该具有良好的扩展性,以适配网络接口的局部性。对于特殊的网络需求, 可以使用设备插件 API 作为临时方案,以减少网络接口的局限性。
用户故事 #
故事 1: 快速虚拟化的网络功能
要求在一个首选的 NUMA 节点上,既要“网络快”,又能自动完成各个组件(大页,cpu 集,网络设备)的协同。 在大多数场景下,只有极少数的 NUMA 节点才能满足。
故事 2: 加速神经网络训练
NUMA 节点中的已分配的 CPU 和设备,可满足神经网络训练的加速器和独占的 CPU 的需求,以达到性能最优。
提议 #
主要思想:两相拓扑一致性协议 拓扑亲和性在容器级别,与设备和 CPU 的亲和类似。在 Pod 准入期间, 一个新组件可以从设备管理器和 CPU 管理器收集 Pod 中每个容器的配置,这个组件名为拓扑管理器。 当这些组件进行资源分配时,拓扑管理器扮演本地对齐的预分配角色。 我们希望各个组件能利用 Pod 中隐含的 QoS 类型进行优先级排序,以满足局部重要性最优。
提议修改点 #
#
新概念:拓扑管理器
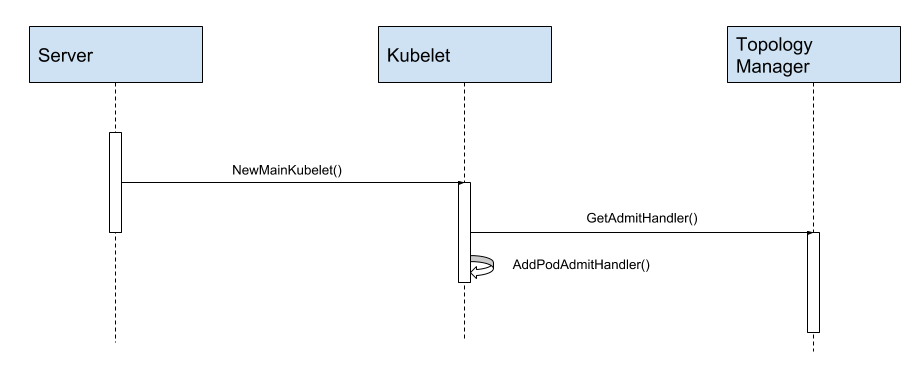
这个提议主要关注 kubelet 中一个新组件,叫做拓扑管理器。拓扑管理器实现了 Pod 的 Admit() 接口,
并参与 kubelet 的对 Pod 的准入。当 Admit() 方法被调用,拓扑管理器根据 kubelet 标志,
逐个 Pod 或逐个容器收集 kubelet 其他组件的的拓扑信息。
如果提示不兼容,拓扑管理器可以选择拒绝 Pod,这是由 kubelet 配置的拓扑策略所决定的。 拓扑管理器支持 4 中策略:none(默认)、best-erffort、restricted 和 single-numa-node。
拓扑信息中包含了对本地资源的偏好。拓扑信息当前由以下组成:
- 位掩码表——可能满足请求的 NUMA 节点
- 首选属性
- 属性定义如下:
- 每个拓扑信息提供者,都有一个满足请求的可能资源分配,这样就可以尽可能减少 NUMA 节点数量(节点为空那样计算)
- 有一种可能的分配方式,相关 NUMA 节点联合总量,不大于任何个单个资源的的请求量
- 属性定义如下:
Pod 的有效资源请求/限制
所有提供拓扑信息的组件,都应该先考虑资源的请求和限制,再计算得出可靠的拓扑提示, 这个规则是由 init 容器的概念定义的。
Pod 对资源的请求和限制的有效值,由以下 2 个条件中较大的一个决定:
- 所有 init 容器中,请求或限制的最大值(
max([]initcontainer.Request),max([]initcontainer.Limit)) - 所有应用的请求和限制的总和(
sum([]containers.Request),sum([]containers.Limit))
下面这个例子简要说明它是如何工作的:
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
containers:
- name: appContainer1
resources:
requests:
cpu: 2
memory: 1G
- name: appContainer2
resources:
requests:
cpu: 1
memory: 1G
initContainers:
- name: initContainer1
resources:
requests:
cpu: 2
memory: 1G
- name: initContainer2
resources:
requests:
cpu: 2
memory: 3G
#资源请求的有效值:CPU: 3, Memory: 3G
debug/ephemeral 容器不能指定资源请求/限制,因为不会影响拓扑提示的结果。
范围
拓扑管理器将根据新 kubelet 标志 --topology-manager-scope 的值,
尝试逐个 Pod 或逐个容器地对资源进行对齐。该标志可以显示的值详细如下:
-
Container(默认):逐个容器地收集拓扑信息。 然后,拓扑策略将为每个容器单独调整资源,只有调整成功,Pod 准入成功。
-
Pod:逐个 Pod 地收集拓扑信息。 然后,拓扑策略将为所有容器集体调整资源,只有调整成功,Pod 准入成功。
策略
- none(默认):kubelet 不会参考拓扑管理器的决定
- best-effort:拓扑管理器会基于拓扑信息,给出首选分配。 在此策略下,即使分配结果不合理,Pod 也成功准入。
- restricted:与 best-effort 不同,在此策略下,如果分配结果不合理,Pod 会被拒绝。
同时,因准入失败,进入
Terminated状态。 - single-numa-node:拓扑管理器会在 NUMA 节点上强制执行资源分配,如果分配失败,Pod 会被拒绝。
同时,因准入失败,进入
Terminated状态。
拓扑管理器组件默认被禁用,直到从 alpha 到 beta 级别解禁。
亲和计算
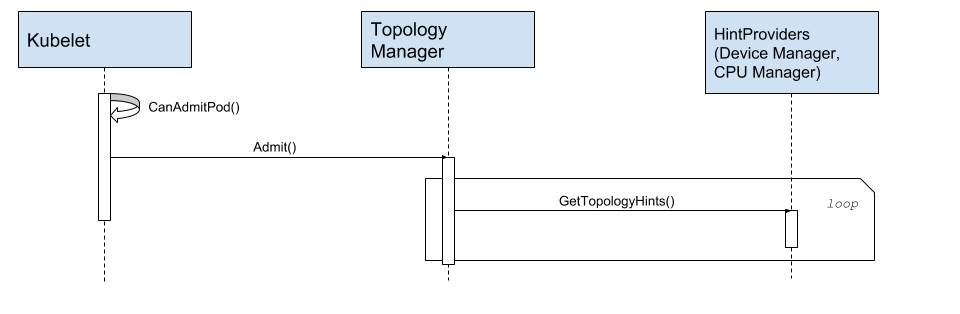
拓扑管理策略基于收集的所有拓扑信息,执行亲和计算,然后决定接受或拒绝 Pod。
亲和算法
- best-effort/restricted (亲和算法相同)
- 循环遍历所有拓扑信息提供者,并以列表保存每个信息源的返回。
- 遍历步骤 1 中的列表,执行按位与运算,合并为单个亲和信息。如果循环中任何字段的亲和返回了 false,则最终结果该字段也为 false。
- 返回的亲和信息的最小集,最小集意味着至少有一个 NUMA 节点满足资源请求。
- 如果没有找到任何 NUMA 节点集的提示,则返回一个默认提示,该值包含了所有 NUMA 节点,并把首选设置为 false。
- single-numa-node
- 循环遍历所有拓扑信息提供者,并以列表保存每个信息源的返回
- 过滤步骤 1 中累积的列表,使其只包含具有单个 NUMA 节点和空 NUMA 节点的提示
- 遍历步骤 1 中的列表,执行按位与运算,合并为单个亲和信息。如果循环中任何字段的亲和返回了 false,则最终结果该字段也为 false
- 如果没有找到具有单 NUMA 节点集的提示,则返回一个默认提示,该提示包含所有 NUMA 节点集并且首选设置为 false。
策略决断
- best-effort:总是遵循拓扑信息提示,准入 Pod
- restricted:只有拓扑提示的首选字段为 true,才准入 Pod
- single-numa-node:既需要拓扑的首选字段为 true,又需要位掩码设置为单个 NUMA 节点,才准入 Pod
新的接口
清单:拓扑管理器和相关接口
package bitmask
// BitMask interface allows hint providers to create BitMasks for TopologyHints
type BitMask interface {
Add(sockets ...int) error
Remove(sockets ...int) error
And(masks ...BitMask)
Or(masks ...BitMask)
Clear()
Fill()
IsEqual(mask BitMask) bool
IsEmpty() bool
IsSet(socket int) bool
IsNarrowerThan(mask BitMask) bool
String() string
Count() int
GetSockets() []int
}
func NewBitMask(sockets ...int) (BitMask, error) { ... }
package topologymanager
// Manager interface provides methods for Kubelet to manage Pod topology hints
type Manager interface {
// Implements Pod admit handler interface
lifecycle.PodAdmitHandler
// Adds a hint provider to manager to indicate the hint provider
//wants to be consoluted when making topology hints
AddHintProvider(HintProvider)
// Adds Pod to Manager for tracking
AddContainer(Pod *v1.Pod, containerID string) error
// Removes Pod from Manager tracking
RemoveContainer(containerID string) error
// Interface for storing Pod topology hints
Store
}
// TopologyHint encodes locality to local resources. Each HintProvider provides
// a list of these hints to the TopoologyManager for each container at Pod
// admission time.
type TopologyHint struct {
NUMANodeAffinity bitmask.BitMask
// Preferred is set to true when the BitMask encodes a preferred
// allocation for the Container. It is set to false otherwise.
Preferred bool
}
// HintProvider is implemented by Kubelet components that make
// topology-related resource assignments. The Topology Manager consults each
// hint provider at Pod admission time.
type HintProvider interface {
// GetTopologyHints returns a map of resource names with a list of possible
// resource allocations in terms of NUMA locality hints. Each hint
// is optionally marked "preferred" and indicates the set of NUMA nodes
// involved in the hypothetical allocation. The topology manager calls
// this function for each hint provider, and merges the hints to produce
// a consensus "best" hint. The hint providers may subsequently query the
// topology manager to influence actual resource assignment.
GetTopologyHints(Pod v1.Pod, containerName string) map[string][]TopologyHint
// GetPodLevelTopologyHints returns a map of resource names with a list of
// possible resource allocations in terms of NUMA locality hints.
// The returned map contains TopologyHint of requested resource by all containers
// in a Pod spec.
GetPodLevelTopologyHints(Pod *v1.Pod) map[string][]TopologyHint
// Allocate triggers resource allocation to occur on the HintProvider after
// all hints have been gathered and the aggregated Hint is available via a
// call to Store.GetAffinity().
Allocate(Pod *v1.Pod, container *v1.Container) error
}
// Store manages state related to the Topology Manager.
type Store interface {
// GetAffinity returns the preferred affinity as calculated by the
// TopologyManager across all hint providers for the supplied Pod and
// container.
GetAffinity(PodUID string, containerName string) TopologyHint
}
// Policy interface for Topology Manager Pod Admit Result
type Policy interface {
// Returns Policy Name
Name() string
// Returns a merged TopologyHint based on input from hint providers
// and a Pod Admit Handler Response based on hints and policy type
Merge(providersHints []map[string][]TopologyHint) (TopologyHint, lifecycle.PodAdmitResult)
}
图:拓扑管理器组件
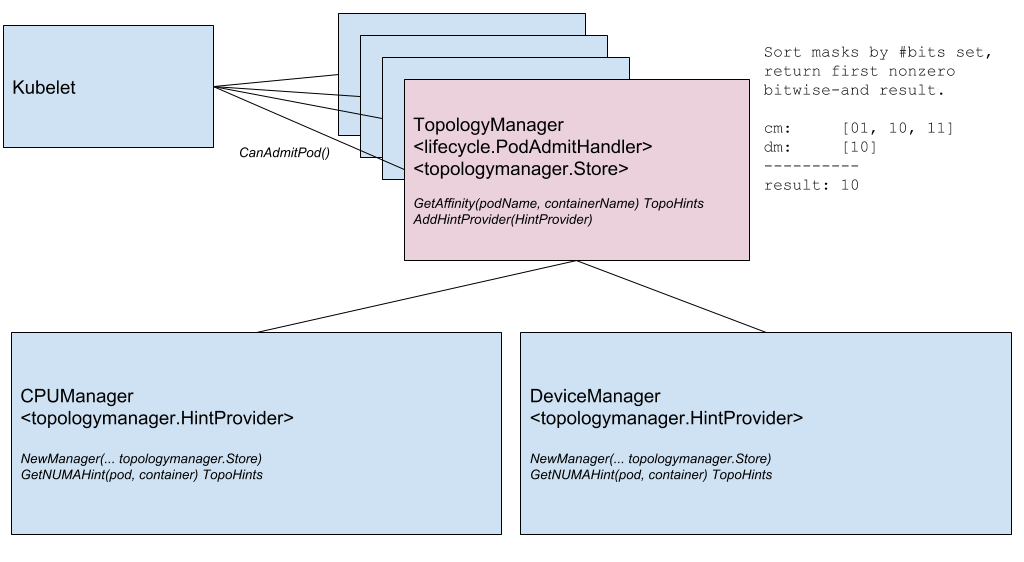
图:拓扑管理器实例化并出现在 Pod 准入生命周期中
特性门禁和 kubelet 启动参数 #
将添加一个特性门禁,控制拓扑管理器特性的启动。此门禁将在 Kubelet 启用,并在 Alpha 版本中默认关闭。
-
门禁定义建议:
--feature-gate=TopologyManager=true
如上所述,kubelet 还新增一个标志,用于标识拓扑管理器策略。默认策略将会是 none。
-
策略标志建议:
--topology-manager-policy=none|best-effort|restricted|single-numa-node
根据选择的策略,以下标志将确定应用策略的范围(逐个 Pod 或逐个容器)。范围的默认值是 container
-
范围标志建议:
--topology-manager-scope=container|Pod
现有组件变更 #
- Kubelet 向拓扑管理器咨询 Pod 准入(上面讨论过)
- 添加两个拓扑管理器接口的实现和一个特性门禁
- 当功能门被禁用时,尽可能保证拓扑管理器功能失效。
- 添加一个功能性拓扑管理器,用来查询拓扑信息,以便为每个容器计算首选套接字掩码。
- CPU 管理器添加 2 个方法:
GetTopologyHints()和GetPodLevelTopologyHints()- CPU 管理器的 static 策略在决定 CPU 的亲和性是,调用拓扑管理器的
GetAffinity()方法
- CPU 管理器的 static 策略在决定 CPU 的亲和性是,调用拓扑管理器的
- 设备管理器添加 2 个方法:
GetTopologyHints()和GetPodLevelTopologyHints()- 在设备插件接口的设备结构中添加
TopologyInfo。 插件在枚举受支持的设备时应该能够确定 NUMA 节点。请参阅下面的协议差异。 - 设备管理器决定设备分配时,调用拓扑管理器的
GetAffinity()方法
- 在设备插件接口的设备结构中添加
清单:修改后的设备插件 gRPC 协议
diff --git a/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto b/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
index efbd72c133..f86a1a5512 100644
--- a/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
+++ b/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
@@ -73,6 +73,10 @@ message ListAndWatchResponse {
repeated Device devices = 1;
}
+message TopologyInfo {
+ repeated NUMANode nodes = 1;
+}
+
+message NUMANode {
+ int64 ID = 1;
+}
+
/* E.g:
* struct Device {
* ID: "GPU-fef8089b-4820-abfc-e83e-94318197576e",
* State: "Healthy",
+ * Topology:
+ * Nodes:
+ * ID: 1
@@ -85,6 +89,8 @@ message Device {
string ID = 1;
// Health of the device, can be healthy or unhealthy, see constants.go
string health = 2;
+ // Topology details of the device
+ TopologyInfo topology = 3;
}
图:拓扑管理器提示提供者注册
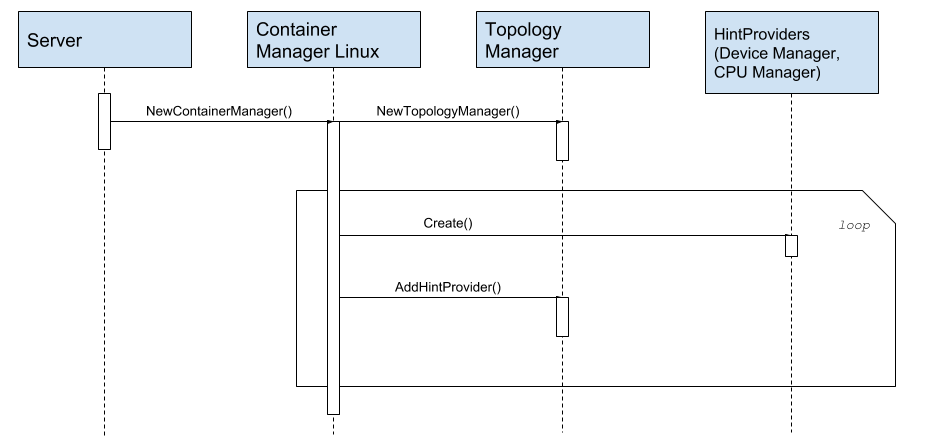
图:拓扑管理器从 HintProvider 获取拓扑提示
此外,我们提议将设备插件接口扩展为“最后一级”过滤器,以帮助影响设备管理器做出的总体分配决策。 下面的差异显示了提议的改动:
diff --git a/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto b/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
index 758da317fe..1e55d9c541 100644
--- a/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
+++ b/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
@@ -55,6 +55,11 @@ service DevicePlugin {
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
+ // GetPreferredAllocation returns a preferred set of devices to allocate
+ // from a list of available ones. The resulting preferred allocation is not
+ // guaranteed to be the allocation ultimately performed by the
+ // `devicemanager`. It is only designed to help the `devicemanager` make a
+ // more informed allocation decision when possible.
+ rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
+
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
@@ -99,6 +104,31 @@ message PreStartContainerRequest {
message PreStartContainerResponse {
}
+// PreferredAllocationRequest is passed via a call to
+// `GetPreferredAllocation()` at Pod admission time. The device plugin should
+// take the list of `available_deviceIDs` and calculate a preferred allocation
+// of size `size` from them, making sure to include the set of devices listed
+// in `must_include_deviceIDs`.
+message PreferredAllocationRequest {
+ repeated string available_deviceIDs = 1;
+ repeated string must_include_deviceIDs = 2;
+ int32 size = 3;
+}
+
+// PreferredAllocationResponse returns a preferred allocation,
+// resulting from a PreferredAllocationRequest.
+message PreferredAllocationResponse {
+ ContainerAllocateRequest preferred_allocation = 1;
+}
+
// - Allocate is expected to be called during Pod creation since allocation
// failures for any container would result in Pod startup failure.
// - Allocate allows kubelet to exposes additional artifacts in a Pod's
使用这个新的 API 调用,设备管理器将在 Pod 准入时调用一个插件, 要求它从可用设备列表中获得一个给定大小的首选设备分配。Pod 中的每个容器都会调用一次。
传给 GetPreferredAllocation() 方法的可用设备列表不一定与系统上可用的完整列表相匹配。
相反,在考虑所有 TopologyHint 之后,设备管理器调用 GetPreferredAllocation() 方法,
是最后一次筛选,方法执行结束必须要做出选择。因此,这个可用列表已经经过 TopologyHint 的预筛选。
首选分配并不保证是最终由设备管理器执行的分配。它的设计只是为了帮助设备管理者在可能的情况下做出更明智的分配决策。
在决定首选分配时,设备插件可能会考虑设备管理器不知道的内部拓扑约束。分配 NVIDIA 图形处理器对, 总是包括一个 NVLINK,就是一个很好的例子。
在一台 8 GPU 的机器上,如果需要 2 个 GPU,NVLINK 提供的最佳连接对可能是:
{{0,3}, {1,2}, {4,7}, {5,6}}
使用 GetPreferredAllocation () ,NVIDIA 设备插件可以将这些首选分配之一转发给设备管理器,
如果仍然有合适的设备集可用的话。如果没有这些额外的信息,
设备管理器最终会在 TopologyHint 过滤之后从可用的 gpu 列表中随机选择 gpu。
这个 API 允许它最终以最小的成本执行更好的分配。