概述 #
在可用计算资源较少时,kubelet 为保证节点稳定性,会主动地结束一个或多个 pod 以回收短缺地资源, 这在处理内存和磁盘这种不可压缩资源时,驱逐 pod 回收资源的策略,显得尤为重要。 下面来具体研究下 Kubelet Eviction Policy 的工作机制。
- kubelet 预先监控本节点的资源使用,防止资源被耗尽,保证节点稳定性。
- kubelet 会预先 Fail N(>=1) 个 Pod,以回收出现紧缺的资源。
- kubelet 在 Fail 一个 pod 时,kill 掉 pod 内所有 container,并设置 pod.status.phase = Failed。
- kubelet 按照事先设定好的 Eviction Threshold 来触发驱逐动作,实现资源回收。
驱逐信号 #
在源码 pkg/kubelet/eviction/api/types.go 中定义了以下及几种 Eviction Signals:
| Eviction Signal | Description |
|---|---|
| memory.available | := node.status.capacity[memory] - node.stats.memory.workingSet |
| nodefs.available | := node.stats.fs.available |
| nodefs.inodesFree | := node.stats.fs.inodesFree |
| imagefs.available | := node.stats.runtime.imagefs.available |
| imagefs.inodesFree | := node.stats.runtime.imagefs.inodesFree |
| allocatableMemory.available | := pod.allocatable - pod.workingSet |
| pid.available | := node.MaxPID - node.NumOfRunningProcesses |
上表主要涉及三个方面,memory、file system 和 pid。其中 kubelet 值支持 2 种文件系统分区:
- nodefs:kubelet 用来存储 volume 和 daemon logs 等
- imagesfs:容器运行时 ( docker 等)用来保存镜像和容器的 writable layer
驱逐阈值 #
kubelet 的入参接收用户定义的 eviction signal 和 eviction threshold 的映射关系,格式如下:
[eviction-signal] [opterator] [quantity]
- 支持的 signal 如上表所示;
- operator 是关系运算符,例如
<; - quantity 是驱逐阈值,合法的值必须是 kubernetes 使用的数量表示,例如 1Gi 和 10% 等;
软驱逐策略 #
Soft Eviction Thresholds,它与以下三个参数配合使用:
eviction-soft:(e.g. memory.available<1.5Gi) 触发软驱逐的阈值;eviction-soft-grace-period:(e.g. memory.available=1m30s) 当达到软驱逐的阈值,需要等待的时间; 在这段时间内,每 10s 会重新获取监控数据并更新 threshold 值, 如果在等待期间,最后一次的数据仍然超过阈值,才会触发驱逐 pod 的行为。eviction-max-pod-grace-period:(e.g. 30s) 当满足软驱逐阈值并终止 pod 时允许的最大宽限期值。 如果待 Evict 的 Pod 指定了pod.Spec.TerminationGracePeriodSeconds, 则取min(eviction-max-pod-grace-period, pod.Spec.TerminationGracePeriodSeconds)作为 Pod Termination 真正的 Grace Period。
因此,在软驱逐策略下,从 kubelet 检测到驱逐信号达到了阈值设定开始,到 pod 真正被 kill 掉,
共花费的时间是:sum(eviction-max-pod-grace-period, min(eviction-max-pod-grace-period, pod.Spec.TerminationGracePeriodSeconds))
硬驱逐 #
Hard Eviction Thresholds 比 Soft Eviction Thresholds 简单粗暴,没有宽限期, 即使 pod 配置了 pod.Spec.TerminationGracePeriodSeconds,一旦达到阈值配置, kubelet 立马回收关联的短缺资源,并且使用的就立即结束,而不是优雅终止。 此特性已经标记为 Deprecated。
源码 pkg/kubelet/apis/config/v1beta1/defaults_linux.go 给出了默认的硬驱逐配置:
- memory.available < 100Mi
- nodefs.available < 10%
- nodefs.inodesFree < 5%
- imagefs.available < 15%
驱逐周期 #
有了驱逐信号和阈值,也有了策略,接下来就是 Eviction Monitoring Interval。
kubelet 对应的监控周期,就通过 cAdvisor 的 housekeeping-interval 配置的,默认 10s。
节点状态 #
kubelet 监测到配置的驱逐策略被触发,会将驱逐信号映射到对应的节点状态。
Kubelet 会将对应的 Eviction Signals 映射到对应的 Node Conditions,
源码 [pkg/kubelet/eviction/helpers.go],其映射关系如下:
| 节点状态 | 驱逐信号 | 描述 |
|---|---|---|
| MemoryPressure | memory.avaliable, allocatableMemory.available | 节点或 pod 的可用内存触发驱逐阈值 |
| DiskPressure | nodefs.avaliable, nodefs.inodesFree, imagefs.available, imagesfs.inodesFree | 节点的 root fs 或 i mage fs 上的可用磁盘空间和索引节点已满足收回阈值 |
| PIDPressure | pid.available | 节点的可用 PID 触发驱逐阈值 |
kubelet 映射了 Node Condition 之 后,会继续按照--node-status-update-frequency(default 10s) 配置的时间间隔,
周期性的与 kube-apiserver 进行 node status updates。
节点状态振荡 #
考虑这样一种场景,节点上监控到 soft eviction signal 的值,始终在 eviction threshold 上下波动, 那么 kubelet 就会将该 node 对应的 node condition 在 true 和 false 之间来回切换。 给 kube-scheduler 产生错误的调度结果。
因此,kubelet 添加参数 eviction-pressure-transition-period (default 5m0s) 配置,
使 Kubelet 在解除由 Evicion Signal 映射的 Node Pressure 之前,必须等待 5 分钟。
驱逐逻辑添加了一步:
Soft Evction Singal高于Soft Eviction Thresholds时, Kubelet 还是会立刻设置对应的 MemoryPressure 或 DiskPressure 为 True。- 当 MemoryPressure 或 DiskPressure 为 True 的前提下,
发生了
Soft Evction Singal低于Soft Eviction Thresholds的情况, 则需要等待eviction-pressure-transition-period(default 5m0s) 配置的这么长时间, 才会将 condition pressure 切换回 False。
一句话总结:Node Condition Pressure 成为 True 容易,切换回 False 则要等eviction-pressure-transition-period。
回收节点层级资源 #
如果满足驱逐阈值并超过了宽限期,kubelet 将启动回收压力资源的过程, 直到它发现低于设定阈值的信号为止。 kubelet 将尝试在驱逐终端用户 pod 前回收节点层级资源。 发现磁盘压力时,如果节点针对容器运行时配置有独占的 imagefs, kubelet 回收节点层级资源的方式将会不同。
使用 imagefs #
- 如果 nodefs 文件系统满足驱逐阈值,kubelet 通过驱逐 pod 及其容器来释放磁盘空间。
- 如果 imagefs 文件系统满足驱逐阈值,kubelet 通过删除所有未使用的镜像来释放磁盘空间。
未使用 imagefs #
- 删除停止运行的 pod/container
- 删除全部没有被使用的镜像
驱逐策略 #
kubelet 根据 Pod 的 QoS Class 实现了一套默认的 Evication 策略, kubelet 首先根据他们对短缺资源的使用是否超过请求来排除 pod 的驱逐行为, 然后通过优先级,然后通过相对于 pod 的调度请求消耗急需的计算资源。图解如下:
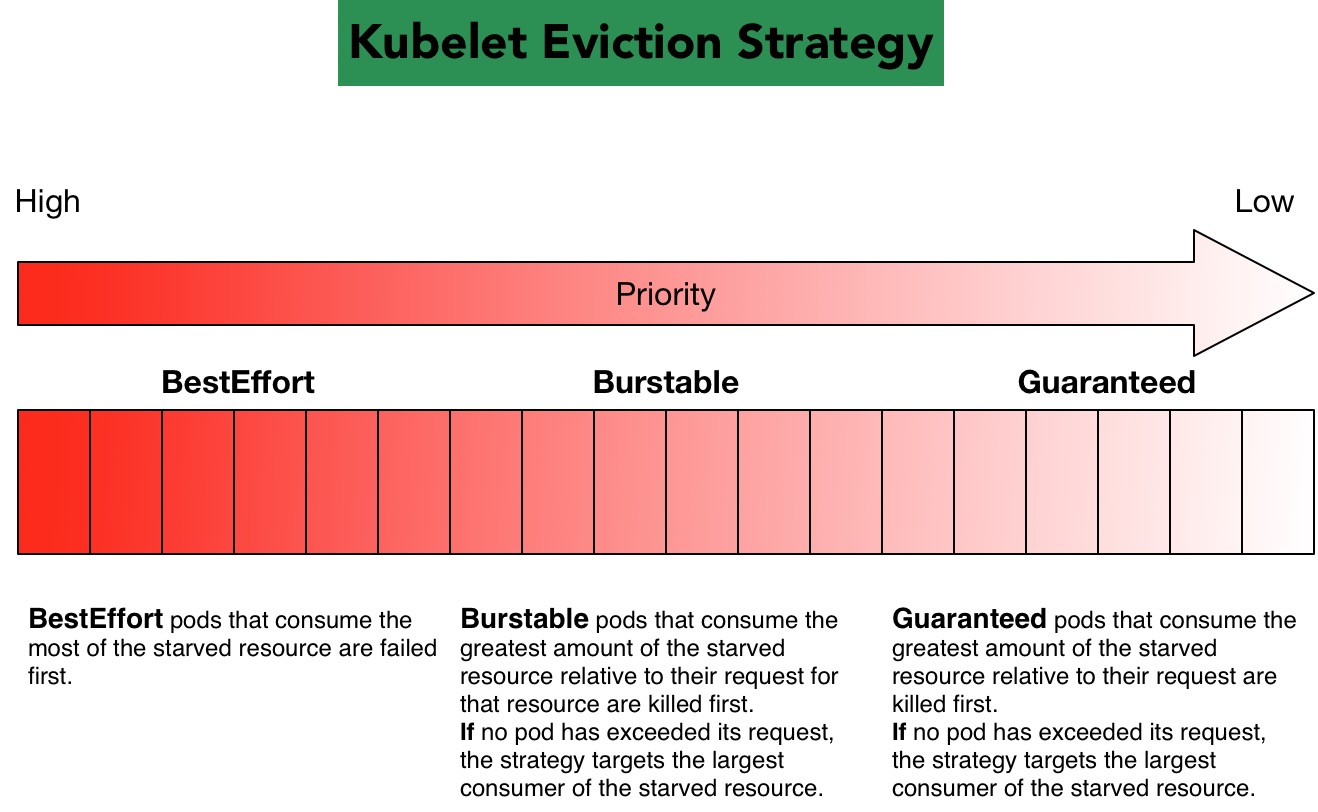
对于每一种 Resource 都可以将容器分为 3 种 QoS Classes: Guaranteed, Burstable 和 Best-Effort, 它们的 QoS 级别依次递减。
BestEffort,按照短缺资源占用量排序,占用量越高,被 kill 的优先级越高;Burstable,对使用量高于请求量的 pod 排序,占用越多,回收优先级越高; 如果没有 pod 的使用超过请求,按照 BestEffort 策略回收;Guaranteed,Guaranteedpod 只有为所有的容器指定了要求和限制并且它们相等时才能得到保证。 由于另一个 pod 的资源消耗,这些 pod 保证永远不会被驱逐。 如果系统守护进程(例如kubelet、docker、和journald) 消耗的资源多于通过system-reserved或kube-reserved分配保留的资源, 并且该节点只有Guaranteed或Burstablepod 使用少于剩余的请求, 然后节点必须选择驱逐这样的 pod 以保持节点的稳定性并限制意外消耗对其他 pod 的影响。 在这种情况下,它将首先驱逐优先级最低的 pod。
最小驱逐回收 #
有些情况下,可能只回收一小部分的资源就能使得 Evication Signal 的值低于 eviction thresholds。
但是,可能随着资源使用的波动或者新的调度 Pod 使得在该 Node 上很快又会触发 evict pods 的动作,
eviction 毕竟是耗时的动作,所以应该尽量避免这种情况的发生。
为了减少这类问题,每次 Evict Pods 后,Node 上对应的 Resource 不仅要比 Eviction Thresholds 低,
还要保证最少比 Eviction Thresholds,再低 --eviction-minimum-reclaim 中配置的数量。
例如使用下面的配置:
--eviction-hard=memory.available<500Mi,nodefs.available<1Gi,imagefs.available<100Gi
--eviction-minimum-reclaim="memory.available=0Mi,nodefs.available=500Mi,imagefs.available=2Gi"
如果 memory.available 驱逐阈值被触发,kubelet 将保证 memory.available 至少为 500Mi。
对于 nodefs.available,kubelet 将保证 nodefs.available 至少为 1.5Gi。
对于 imagefs.available,kubelet 将保证 imagefs.available 至少为 102Gi,
直到不再有相关资源报告压力为止。
所有资源的默认 eviction-minimum-reclaim 值为 0。