Profiling 是指在程序执行过程中,收集能够反映程序执行状态的数据。 在软件工程中,性能分析(performance analysis,也称为 profiling), 是以收集程序运行时信息为手段研究程序行为的分析方法,是一种动态程序分析的方法。
什么是 pprof #
Go 语言自带的 pprof 库就可以分析程序的运行情况,并且提供可视化的功能。它包含两个相关的库:
- runtime/pprof 对于只跑一次的程序,例如每天只跑一次的离线预处理程序,调用 pprof 包提供的函数,手动开启性能数据采集。
- net/http/pprof 对于在线服务,对于一个 HTTP Server,访问 pprof 提供的 HTTP 接口,获得性能数据。 当然,实际上这里底层也是调用的 runtime/pprof 提供的函数,封装成接口对外提供网络访问。
pprof 的作用 #
下表来自 golang pprof 实战
| 类型 | 描述 | 备注 |
|---|---|---|
| allocs | 内存分配情况的采样信息 | 可以用浏览器打开,但可读性不高 |
| blocks | 阻塞操作情况的采样信息 | 可以用浏览器打开,但可读性不高 |
| cmdline | 当前程序的命令行调用 | 可以用浏览器打开,显示编译文件的临时目录 |
| goroutine | 当前所有协程的堆栈信息 | 可以用浏览器打开,但可读性不高 |
| heap | 堆上内存使用情况的采样信息 | 可以用浏览器打开,但可读性不高 |
| mutex | 锁争用情况的采样信息 | 可以用浏览器打开,但可读性不高 |
| profile | CPU 占用情况的采样信息 | 浏览器打开会下载文件 |
| threadcreate | 系统线程创建情况的采样信息 | 可以用浏览器打开,但可读性不高 |
| trace | 程序运行跟踪信息 | 浏览器打开会下载文件,本文不涉及,可另行参阅 深入浅出 Go trace |
allocs 和 heap 采样的信息一致,不过前者是所有对象的内存分配,而 heap 则是活跃对象的内存分配。
pprof 如何使用 #
我们可以通过报告生成、Web 可视化界面、交互式终端三种方式来使用 pprof。
runtime/pprof #
拿 CPU profiling 举例,增加两行代码,调用 pprof.StartCPUProfile 启动 cpu profiling,
调用 pprof.StopCPUProfile() 将数据刷到文件里:
package main
import "runtime/pprof"
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file")
func main() {
// …
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
// …
}
net/http/pprof #
启动一个端口(和正常提供业务服务的端口不同)监听 pprof 请求:
package main
import (
"log"
"net/http"
_ "net/http/pprof"
"regexp"
)
func handler(wr http.ResponseWriter, r *http.Request) {
var pattern = regexp.MustCompile(`^(\w+)@foo.bar$`)
account := r.URL.Path[1:]
res := pattern.FindSubmatch([]byte(account))
if len(res) > 1 {
wr.Write(res[1])
} else {
wr.Write([]byte("None"))
}
}
func main() {
http.HandleFunc("/", handler)
err := http.ListenAndServe(":8888", nil)
if err != nil {
log.Fatal("ListenAndServe:", err)
}
}
pprof 包会自动注册 handler, 处理相关的请求:
// src/net/http/pprof/pprof.go:71
func init() {
http.Handle("/debug/pprof/", http.HandlerFunc(Index))
http.Handle("/debug/pprof/cmdline", http.HandlerFunc(Cmdline))
http.Handle("/debug/pprof/profile", http.HandlerFunc(Profile))
http.Handle("/debug/pprof/symbol", http.HandlerFunc(Symbol))
http.Handle("/debug/pprof/trace", http.HandlerFunc(Trace))
}
启动服务后,直接在浏览器访问:http://localhost:8888/debug/pprof/,得到如下页面:
关于 goroutine 的信息有两个链接,goroutine 和 full goroutine stack dump, 前者是一个汇总的消息,可以查看 goroutines 的总体情况, 后者则可以看到每一个 goroutine 的状态。 页面具体内容的解读可以参考大彬的文章 实战 Go 内存泄露。
采样分析 #
开始采样之前,需要模拟服务访问,这里用到的是压力测试管径 wrk。
# 启动 500 个 HTTP 连接,30 个线程,持续访问 1 分钟
wrk -c500 -t30 -d1m http://localhost:8888/zzz@foo.bar
报告生成 #
报告生成有 2 种方式:
- runtime/pprof 写入本地文件
- 内置页面下载采样文件
下面以内置页面为例: 在 debug/pprof 页面点击 profile,会在后台进行默认 30s 的数据采样,采样完成后,返回给浏览器一个采样文件,其他命令类似。 然后使用以下命令:
go tool pprof -http=:8080 profile
会在本地 8080 端口启动 http 服务,提供可视化界面:
图中的连线代表对方法的调用,连线上的标签代表指定的方法调用的采样值(例如时间、内存分配大小等), 方框的大小与方法运行的采样值的大小有关。 每个方框由两个标签组成:在 cpu profile 中,一个是方法运行的时间占比, 一个是它在采样的堆栈中出现的时间占比(前者是 flat 时间,后者则是 cumulate 时间占比); 框越大,代表耗时越多或是内存分配越多
点击左上角 VIEW 可以选择不同图形化展示,最常见的火焰图如下:
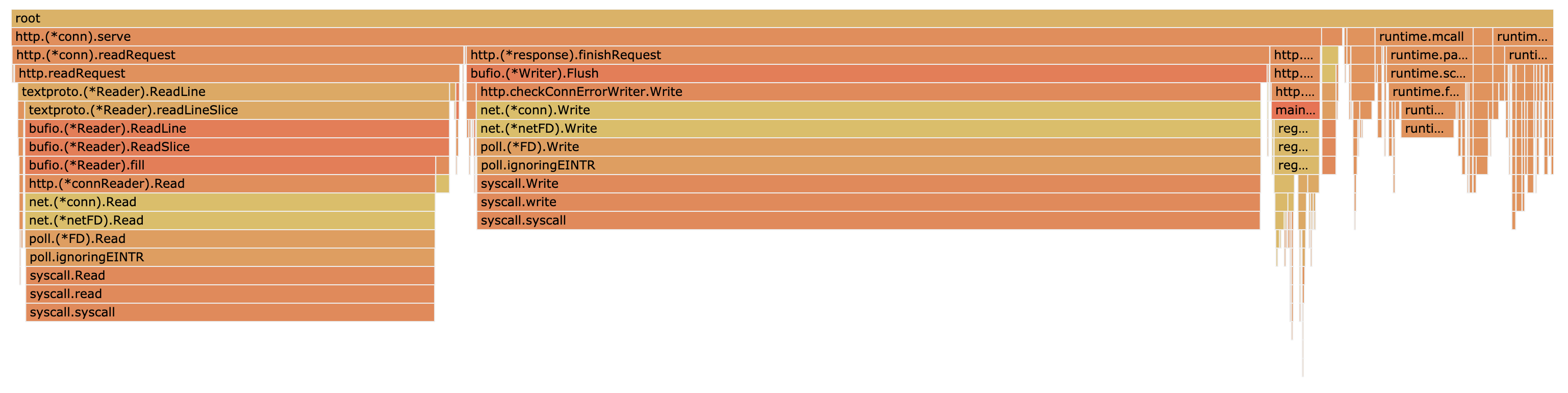
它和一般的火焰图相比刚好倒过来了,调用关系的展现是从上到下。形状越长,表示执行时间越长。
交互式命令 #
除了使用内置的页面采样分析,也直接使用如下命令,不需要通过浏览器直接进入~
# step1:压测工具访问服务
wrk -c500 -t30 -d1m http://localhost:8888/zzz@foo.bar
# step2:采集数据,默认 30s
go tool pprof http://localhost:8888/debug/pprof/profile
其他类似的采集数据命令还有:
# 自定义等待时间 120s
go tool pprof http://localhost:8888/debug/pprof/profile?second=120
# 下载 heap profile
go tool pprof http://localhost:8888/debug/pprof/heap
# 下载 goroutine profile
go tool pprof http://localhost:8888/debug/pprof/goroutine
# 下载 block profile
go tool pprof http://localhost:8888/debug/pprof/block
# 下载 mutex profile
go tool pprof http://localhost:8888/debug/pprof/mutex
下面开始进入命令行交互式模式,使用 top、list、web 等命令:
(pprof) top
Showing nodes accounting for 86.85s, 91.15% of 95.28s total
Dropped 397 nodes (cum <= 0.48s)
Showing top 10 nodes out of 93
flat flat% sum% cum cum%
75.37s 79.10% 79.10% 75.60s 79.35% syscall.syscall
3.79s 3.98% 83.08% 3.81s 4.00% runtime.kevent
1.52s 1.60% 84.68% 1.53s 1.61% runtime.usleep
1.21s 1.27% 85.95% 1.21s 1.27% runtime.pthread_cond_wait
1.20s 1.26% 87.21% 1.20s 1.26% runtime.pthread_kill
0.94s 0.99% 88.19% 0.94s 0.99% runtime.nanotime1
0.89s 0.93% 89.13% 0.89s 0.93% runtime.procyield
0.84s 0.88% 90.01% 0.84s 0.88% indexbytebody
0.59s 0.62% 90.63% 0.59s 0.62% runtime.pthread_cond_signal
0.50s 0.52% 91.15% 0.85s 0.89% runtime.scanobject
得到 5 列数据:
| 字段 | 描述 |
|---|---|
| flat | 本函数的执行耗时 |
| flat% | flat 占 CPU 总时间的比例。程序总耗时 95.28s,syscall.syscall 的 75.60s 占了 79.35% |
| sum% | 前面每一行的 flat 占比总和 |
| cum | 累计量。指该函数加上该函数调用的函数总耗时 |
| cum% | cum 占 CPU 总时间的比例 |
上面的结果没啥有价值的信息,都是 go 的底层调用。使用 list 正则匹配业务代码:
(pprof) list handler
Total: 1.65mins
ROUTINE ======================== main.handler in /Users/yuanhao/Study/GoProjects/testProject/pprof/main.go
30ms 2.63s (flat, cum) 2.65% of Total
. . 6: _ "net/http/pprof"
. . 7: "regexp"
. . 8:)
. . 9:
. . 10:func handler(wr http.ResponseWriter, r *http.Request) {
. 2.38s 11: var pattern = regexp.MustCompile(`^(\w+)@foo.bar$`)
20ms 20ms 12: account := r.URL.Path[1:]
. 160ms 13: res := pattern.FindSubmatch([]byte(account))
. . 14: if len(res) > 1 {
10ms 70ms 15: wr.Write(res[1])
. . 16: } else {
. . 17: wr.Write([]byte("None"))
. . 18: }
. . 19:}
. . 20:
ROUTINE ======================== net/http.(*ServeMux).handler in /usr/local/Cellar/go/1.15.1/libexec/src/net/http/server.go
10ms 10ms (flat, cum) 0.01% of Total
. . 2384: return mux.handler(host, r.URL.Path)
. . 2385:}
. . 2386:
. . 2387:// handler is the main implementation of Handler.
. . 2388:// The path is known to be in canonical form, except for CONNECT methods.
10ms 10ms 2389:func (mux *ServeMux) handler(host, path string) (h Handler, pattern string) {
. . 2390: mux.mu.RLock()
. . 2391: defer mux.mu.RUnlock()
. . 2392:
. . 2393: // Host-specific pattern takes precedence over generic ones
. . 2394: if mux.hosts {
可以看出,main.handler 总共用时 2.63s,其中 regexp.MustComplie 耗时 2.38ms。
罪魁祸首在这里:服务器每次收到请求,都要重新解析正则表达式。
进入下一步,使用 web 命令查看调用链,需要提前安装 graphviz 工具,自动调用浏览器展示下图:
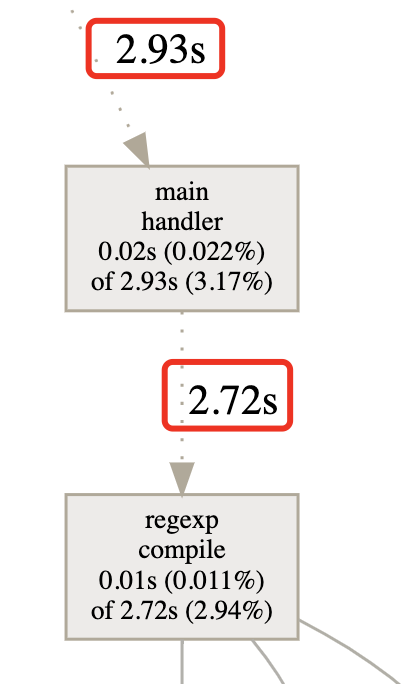
图示与之前看到的调用链图基本一致,聚焦业务代码 main.handler,
可以发现regexp.Compile 耗时明显,因为每次请求过来,都要重新编译正则表达式。